# if your data is in the root folder of your Rstudio project:
treedata <- read.csv('treedata.csv', sep = ";")
species <- read.csv('species.csv', sep = ";")
# if not, give the relative (ex: "data/treedata.csv") or absolute path, ex:
# "Where/ever/you/put/it/treedata.csv"15 Exercise - Data handling
15.1 Exercise
In this exercise you will practice common steps of the data preparation procedure using a dataset that was gathered in a forest in Switzerland.
The main steps are as follows (to solve the tasks, please carefully read the detailed instructions and hints below):
- Read the provided datasets
treedata.csvandspecies.csvto R. - Have a look at the dataset properties.
- Find values that prevent a column you expect to be numeric to do so.
- Does the dataset contain NA-values in
height? How many? - Have a look at the data: Check for implausible values. For now, remove these values.
- Add the species names to the dataset.
- Create a new dataset containing only trees with both, height and dbh measurements.
- Are there any correlations within the new dataset?
- Remove all trees with
rem= F4 from the dataset - Calculate mean dbh by species.
To thoroughly check the dataset and perform the operations, you will need the following functions:
read.csv(): Check the different options using?read.csvstr(): Structure of an objecttable(): Check the optional arguments!merge(): Combine to data.framesas.character(): Change a vector’s class to characteras.numeric(): Change a vector’s class to numeric.%in%is.na()max()summary()complete.cases()cor.test()%>%andgroup_by()andsummarize()from the `dplyr` package (from tidyverse, check demonstration Part 2)
Regarding the solutions, note we don’t expect you to come up with exactly this code - there are many ways to solve the problem. The solutions just give you an idea of a possible solution.
15.1.1 1. Read data
Read the provided datasets treedata.csv and species.csv to R. Use the option stringsAsFactors = FALSE in the function read.csv.
Read the dataset treedata.csv and call it treedata. It has the following columns:
species_code: tree species codedbh: diameter at breast height (1.3 m) [cm]height: total height of the tree [m]. Measured only on a subset of trees.rem: coded values, containing remarks
Read the dataset species.csv and call it species. The dataset consists of the following columns:
species_code: tree species code (matching the one used in treedata.csv)species_scientific: Scientific species namespecies_english: English species name
#### Solution
First, you read in the file using read.csv. You have to specify the correct separator for your dataset, here this is “;”.
15.1.2 2. Dataset properties
Have a look at the properties of the dataset:
- Which classes do the columns have?
- Did you expect these classes?
#### Solution
The data.frame dat contains 4 columns: species, dbh (diameter at breast height [cm]), height [m] and rem, a remark. We expect the following formats:
| column | format |
|---|---|
| species | character |
| dbh | numeric |
| height | numeric |
| rem | factor |
Using str we get an overview of the structure of a dataset:
str(treedata)
## 'data.frame': 287 obs. of 4 variables:
## $ species_code: int 121 121 411 411 411 431 411 411 411 121 ...
## $ dbh : chr "19.3" "21.3" "43" "25.8" ...
## $ height : num NA NA 37.7 NA 34.4 44.4 NA NA NA NA ...
## $ rem : chr "" "" "P7" "F2" ...Column dbh is a character, although we would have expected this one to be class numeric. This indicates, that a letter or special characters are in that column (we do not want these to be in there at all!).
15.1.3 3. Turn character to numeric
One column, which we expect to be numeric, is of class character. Find the value causing this column to be character, set it to NA and turn the column into class numeric.
Note that using ‘is.numeric()’ is not enough, if the column is a factor. This may be the case if you have used the option stringAsFactor = T in read.csv or an older version of R. Use a combination of ‘as.character()’ and ‘as.numeric()’ in that case.
#### Solution
We suspect dbh to contain a character and we want to remove this. With the function ‘table()’, we can check all existing values in the column. There seems to be an ‘X’ in the data.
table(treedata$dbh)
##
## 10.1 10.2 10.4 10.6 10.7 10.9 11.2 11.4 11.5 11.9 12.3 12.5 13 13.2 13.3 13.4
## 1 2 2 1 1 1 2 1 1 1 1 2 1 1 1 1
## 13.8 13.9 14 14.4 14.8 14.9 15.2 15.4 15.5 15.8 16 16.2 16.4 16.6 16.8 17.1
## 3 1 1 6 1 1 3 1 1 1 1 1 1 1 4 1
## 17.2 17.4 17.5 17.6 17.8 17.9 18.1 18.2 18.3 18.7 18.8 19 19.1 19.2 19.3 19.4
## 2 1 1 1 1 2 1 1 1 1 1 1 1 1 1 1
## 19.5 19.8 20 20.2 20.4 20.7 20.8 20.9 2030 21.3 21.6 21.8 21.9 22 22.2 22.3
## 3 3 1 2 1 1 2 2 1 1 4 1 1 1 2 1
## 22.6 22.7 22.9 23.2 23.3 23.6 23.7 23.8 24 24.2 24.3 24.4 24.9 25 25.2 25.3
## 2 1 2 1 1 2 1 1 2 2 2 1 2 1 1 1
## 25.4 25.8 26 26.2 26.3 26.4 26.6 27.4 27.5 27.6 27.8 28.2 28.4 28.6 28.8 29.2
## 4 3 1 2 1 1 1 2 2 1 1 1 2 1 1 1
## 29.4 29.6 29.7 29.8 30.1 30.2 30.4 30.8 31.2 31.3 31.4 31.9 32 32.2 32.3 32.4
## 2 1 1 2 1 1 1 2 1 1 2 1 1 3 1 1
## 32.9 33 33.2 33.3 33.4 33.8 33.9 34.2 34.4 34.6 34.7 34.8 35 35.8 36.5 36.6
## 1 1 1 1 1 3 1 5 1 1 1 1 1 1 1 1
## 36.8 37.1 37.2 37.4 37.8 38.1 38.2 38.3 38.5 39.2 39.4 39.7 39.8 4 4.2 4.6
## 2 1 1 1 2 1 1 1 1 1 1 1 1 3 3 1
## 4.7 40 40.6 40.8 41.3 41.4 41.5 42.3 42.4 43 43.2 43.4 43.6 44.2 44.5 44.8
## 1 1 2 1 1 1 1 1 1 1 1 1 1 1 1 1
## 45.2 45.7 47.8 48 48.7 48.8 49 49.7 49.8 5.1 5.2 5.4 5.5 5.6 5.7 5.8
## 1 1 1 1 1 1 1 1 1 1 3 3 1 1 1 2
## 5.9 51.2 6.2 6.3 6.4 6.5 6.6 6.8 6.9 7 7.2 7.3 7.4 7.6 7.8 8.1
## 2 1 4 2 1 1 2 1 2 1 1 1 2 1 2 1
## 8.2 8.3 8.5 8.8 8.9 9 9.4 9.5 9.6 9.9 X
## 3 2 1 1 2 1 1 2 2 1 1To automatically search for characters, we can check if dbh contains a character that is part of LETTERS (capital letters) or letters:
treedata[treedata$dbh %in% LETTERS | treedata$dbh %in% letters,]
## species_code dbh height rem
## 159 411 X 27.2 F4A more advanced option would be to use grepl. If we are using the solution above, we will only find the value if it is exactly one character. Things get a bit more complicated, if we have special characters, e.g, a *.
x <- rep(c(1, 3, 5, '*', 'AA', ',', 9), 2)
x[grepl("^[A-Za-z]+$", x, perl = T)]
## [1] "AA" "AA"
x[!grepl('[^[:punct:]]', x, perl =T)]
## [1] "*" "," "*" ","We want to set the X in dbh to NA (probably, this is a transcription error, so one could also have a look at the field forms…).
treedata$dbh[treedata$dbh == 'X'] <- NA
str(treedata)
## 'data.frame': 287 obs. of 4 variables:
## $ species_code: int 121 121 411 411 411 431 411 411 411 121 ...
## $ dbh : chr "19.3" "21.3" "43" "25.8" ...
## $ height : num NA NA 37.7 NA 34.4 44.4 NA NA NA NA ...
## $ rem : chr "" "" "P7" "F2" ...Just removing the ‘X’ does not turn a character to numeric! R provides the function as.numeric, which might be of use in this case.
treedata$dbh <- as.numeric(treedata$dbh)
head(treedata$dbh)
## [1] 19.3 21.3 43.0 25.8 38.5 36.815.1.4 4. NA- values in height
Check for NA’s in the column height:
- How many
NA’s do appear in this column? - Did you expect this column to contain
NA’s? Why?
#### Solution
summary(treedata)
## species_code dbh height rem
## Min. :101.0 Min. : 4.00 Min. : 4.60 Length:287
## 1st Qu.:121.0 1st Qu.: 11.60 1st Qu.: 21.75 Class :character
## Median :411.0 Median : 21.60 Median : 29.10 Mode :character
## Mean :329.8 Mean : 29.22 Mean : 26.30
## 3rd Qu.:411.0 3rd Qu.: 31.40 3rd Qu.: 32.62
## Max. :920.0 Max. :2030.00 Max. :110.88
## NA's :1 NA's :221
sum(is.na(treedata$height))
## [1] 221
table(is.na(treedata$height))
##
## FALSE TRUE
## 66 221
nrow(treedata[is.na(treedata$height),])
## [1] 221
table(treedata$height, useNA = 'ifany')
##
## 4.6 4.7 4.8 5.7 5.8 6.1 6.2 6.8 7.3 7.9 10.8
## 1 2 1 1 1 1 1 1 1 1 1
## 11.1 11.3 11.5 14.2 21.7 21.9 22 22.4 23.3 23.8 24.5
## 1 1 1 1 1 1 1 2 1 2 1
## 24.8 26.1 27.2 27.5 27.8 28.6 29 29.2 29.4 29.8 29.9
## 1 1 1 2 1 1 1 1 1 1 1
## 30.2 30.3 30.4 31.3 31.5 31.9 32 32.1 32.3 32.4 32.7
## 1 2 1 1 1 1 2 1 1 1 1
## 32.8 33.2 33.5 33.8 34.2 34.4 35.4 35.8 37.7 38.2 38.6
## 1 1 1 1 1 1 1 1 2 1 1
## 39 40.8 44.4 110.88 <NA>
## 1 1 1 1 221- The dataset contains 221
NA. - Since height has been measured only on a subset of the trees, we expect this column to contain
NA-values.
15.1.5 5. Implausible values
The dataset contains some implausible values (completely out of range!). Find and replace these values with NA.
#### Solution
What values are implausible? The dataset contains different species. A value which is plausible for species A might be implausible for species B. However, for now, we will not go into the details here.
Do a visual check of the dataset
boxplot(treedata$height, main = 'Height')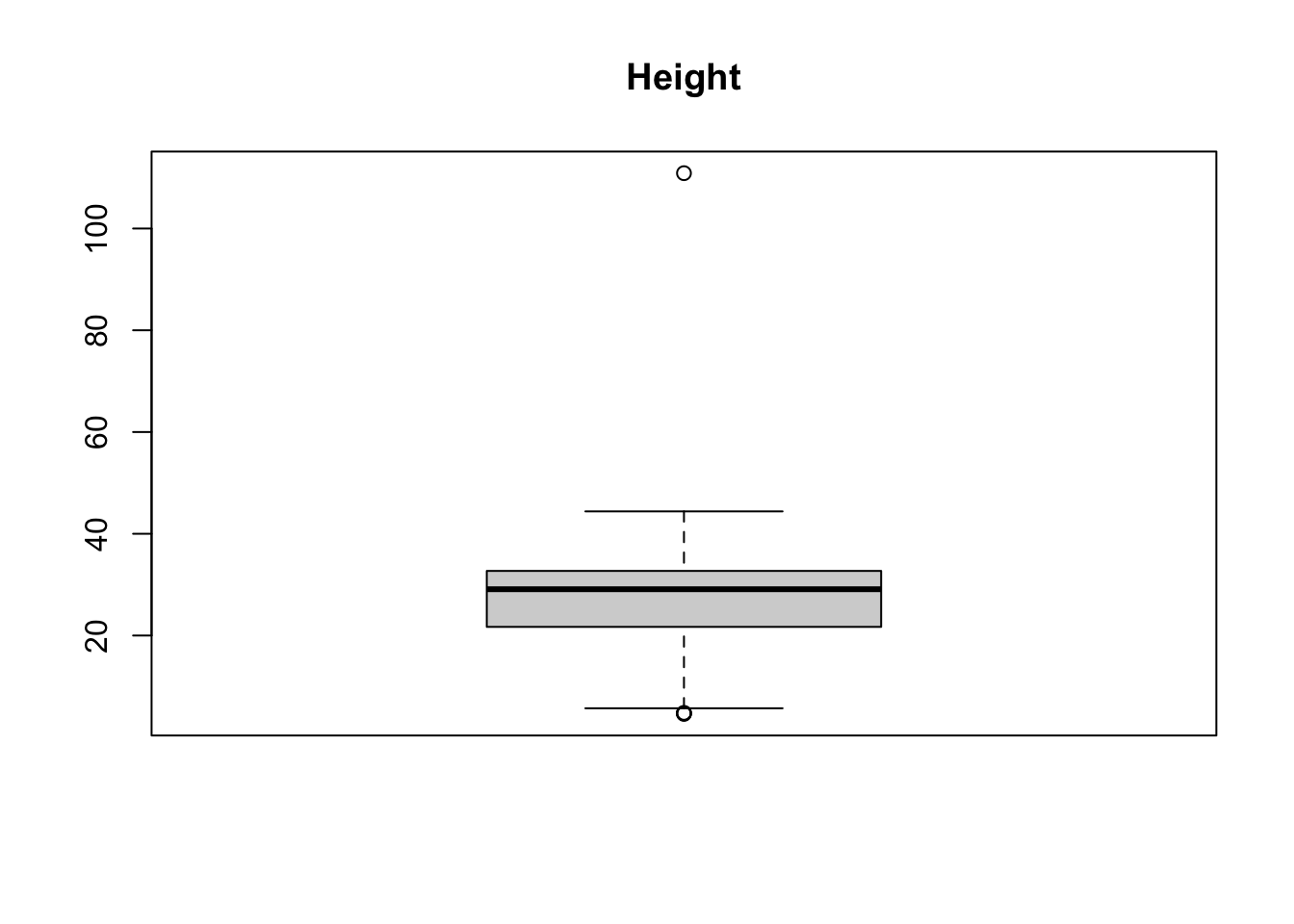
boxplot(treedata$dbh, main ='DBH')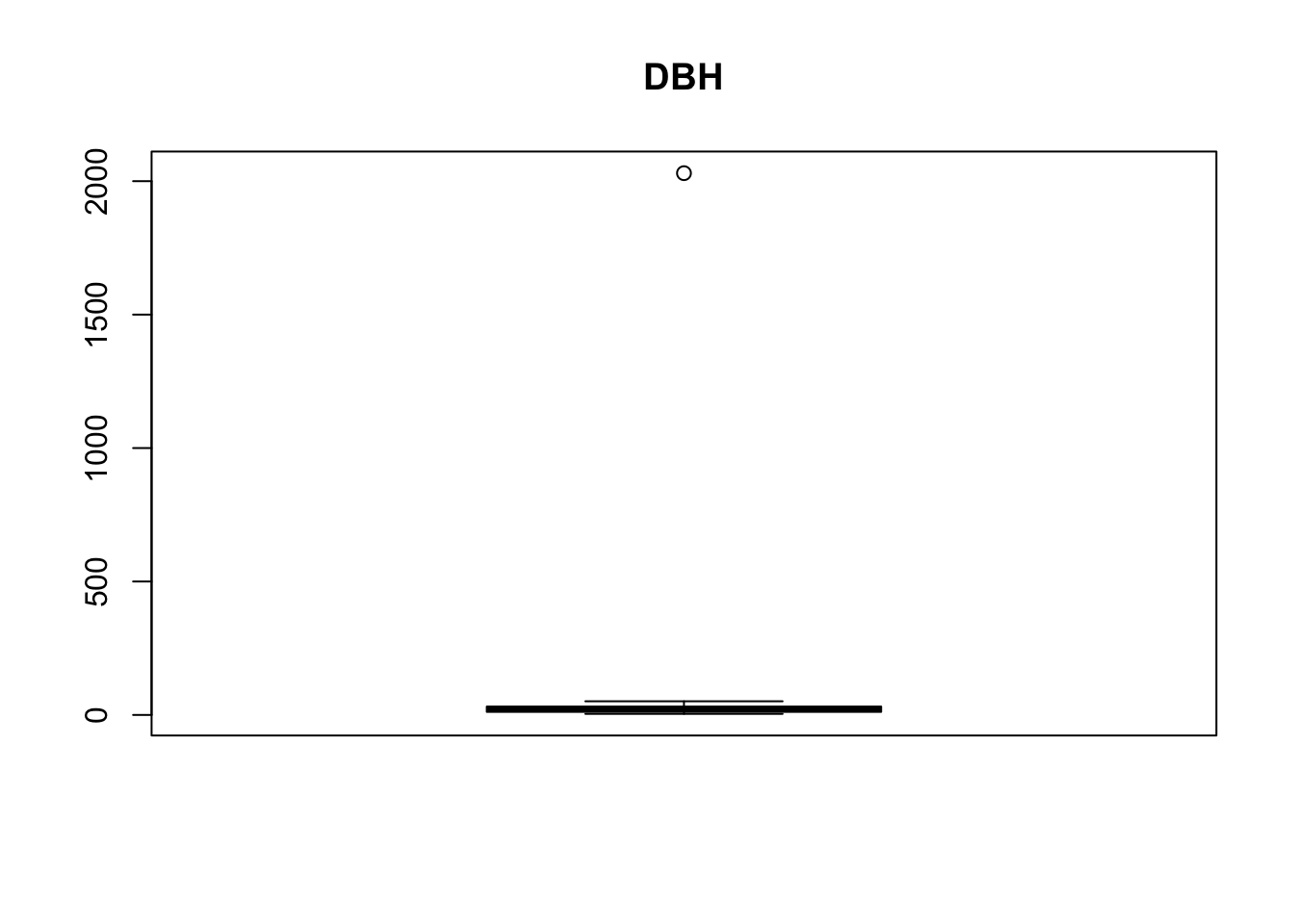
max(treedata$dbh, na.rm = T)
## [1] 2030
max(treedata$height, na.rm = T)
## [1] 110.88
treedata[treedata$dbh > 500 & !is.na(treedata$dbh),]
## species_code dbh height rem
## 114 411 2030 NA F2
treedata[treedata$height > 50 & !is.na(treedata$height),]
## species_code dbh height rem
## 234 411 36.6 110.88There seems to be one outlier in both datasets which can be seen as implausible: No tree is more than 100 m of height and no tree has a diameter > 20 m (These values can be considered implausible for trees in Switzerland).
We will now remove these values from our dataset by setting them to NA - this might not always be the best option, there are also statistical models that can account for such errors!
treedata$dbh[treedata$dbh > 500] <- NA
treedata$height[treedata$height > 50] <- NA
boxplot(treedata$dbh, main = 'DBH')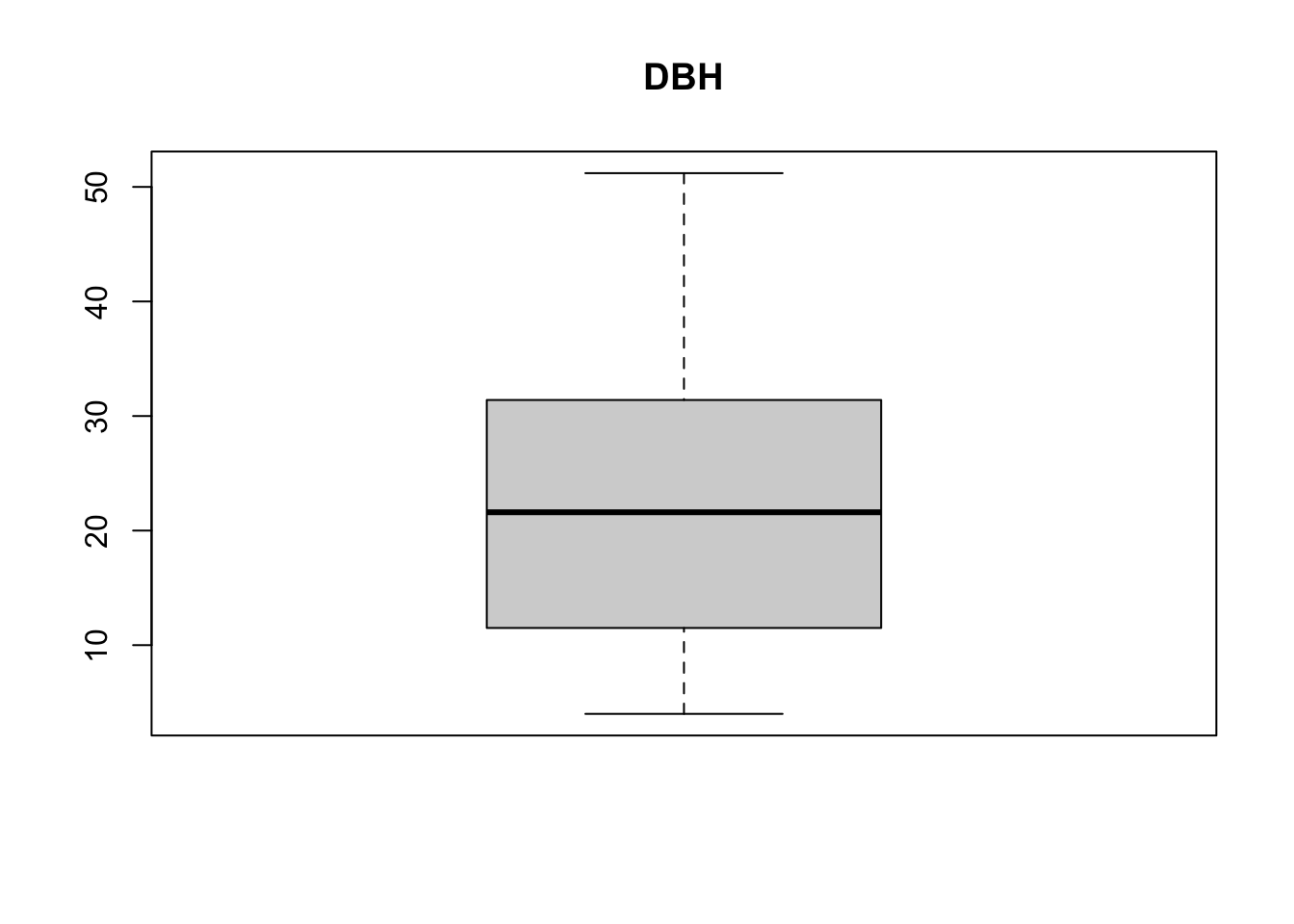
boxplot(treedata$height, main = 'Height')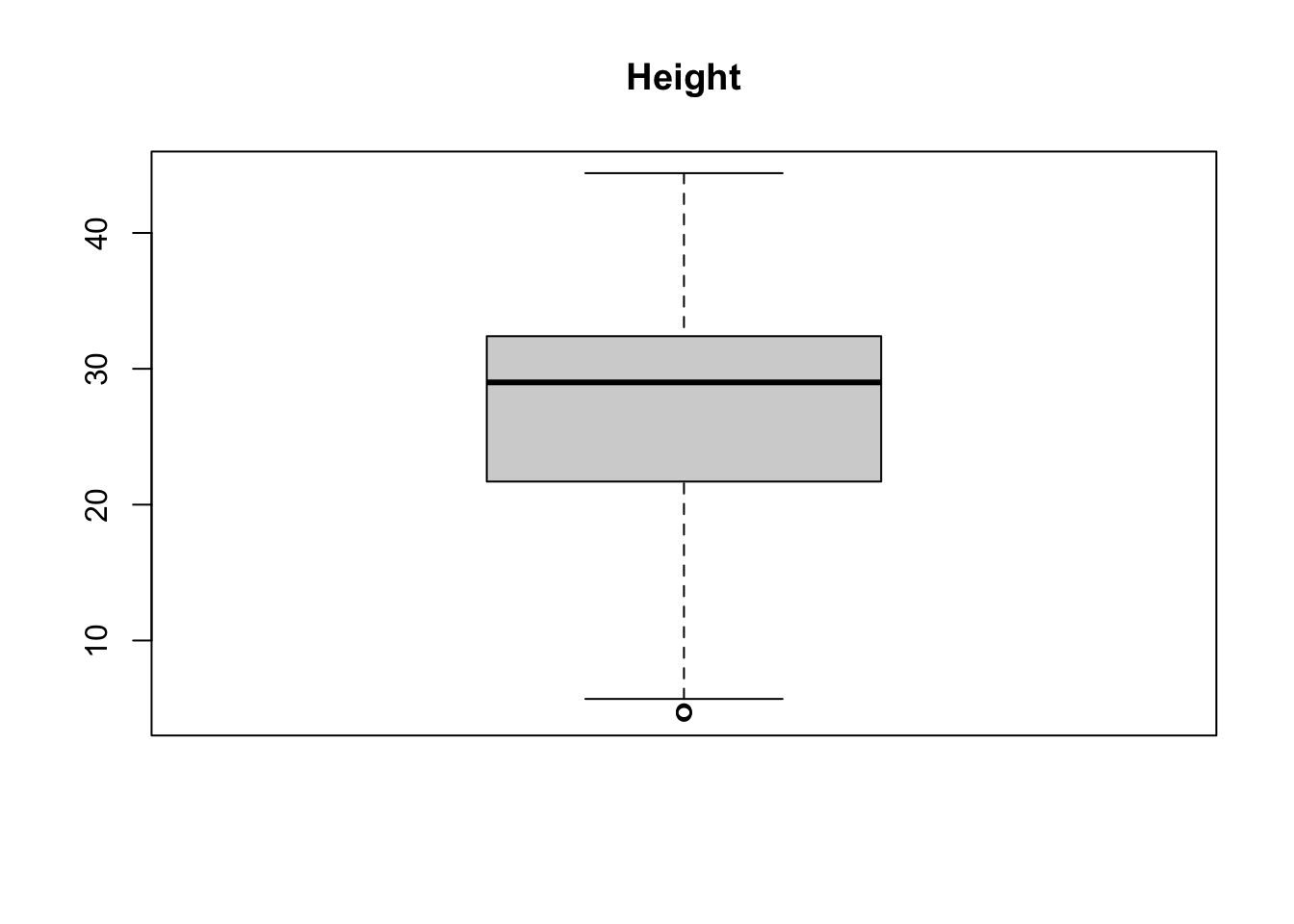
15.1.6 6. Add species names
Add the species names from the species dataset to the treedata dataset.
Hint: ?merge
#### Solution
Use merge to add species names to the dataset treedata. For adding only one column, match is a helpful function.
treedata <- merge(treedata, species, by = "species_code")
head(treedata)
## species_code dbh height rem species_scientific species_english
## 1 101 8.1 5.7 Picea abies (L.) H. Karst. Norway Spruce
## 2 101 10.4 NA Picea abies (L.) H. Karst. Norway Spruce
## 3 101 5.2 NA S0 Picea abies (L.) H. Karst. Norway Spruce
## 4 101 9.6 NA Picea abies (L.) H. Karst. Norway Spruce
## 5 101 8.2 6.2 Picea abies (L.) H. Karst. Norway Spruce
## 6 101 7.4 6.1 Picea abies (L.) H. Karst. Norway Spruce
# Alternative using match():
# treedata$species_english <- species$species_english[match(treedata$species_code, species$species_code)]15.1.7 7. Remove F4
The remark F4 indicates, that the dbh-measurements might be flawed. Remove these trees from treedata.
#### Solution
treedata <- treedata[!treedata$rem %in% 'F4', ] #OR
treedata <- treedata[treedata$rem != 'F4', ]15.1.8 8. Select trees that contain both dbh and height measurements
Subset treedata to trees where both height and dbh measurements were carried out. Call the result dbh_height.
#### Solution
This can be done using complete.cases using
dbh_height <- treedata[complete.cases(treedata$dbh, treedata$height),]
# or filter() in dplyr from tidyverse
library(tidyverse)
## ── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
## ✔ dplyr 1.2.0 ✔ readr 2.2.0
## ✔ forcats 1.0.1 ✔ stringr 1.6.0
## ✔ ggplot2 4.0.2 ✔ tibble 3.3.1
## ✔ lubridate 1.9.5 ✔ tidyr 1.3.2
## ✔ purrr 1.2.1
## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()
## ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
dbh_height2 <- treedata %>% filter(!is.na(dbh) & !is.na(height))15.1.9 9. Correlations?
Check for correlations in the dataset dbh_height. Use a test and plot height vs dbh.
#### Solution
cor.test(dbh_height$dbh
, dbh_height$height)
##
## Pearson's product-moment correlation
##
## data: dbh_height$dbh and dbh_height$height
## t = 13.147, df = 47, p-value < 2.2e-16
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.8066074 0.9348068
## sample estimates:
## cor
## 0.8866893
plot(dbh_height$dbh
, dbh_height$height
, ylab = 'Height'
, xlab = 'DBH')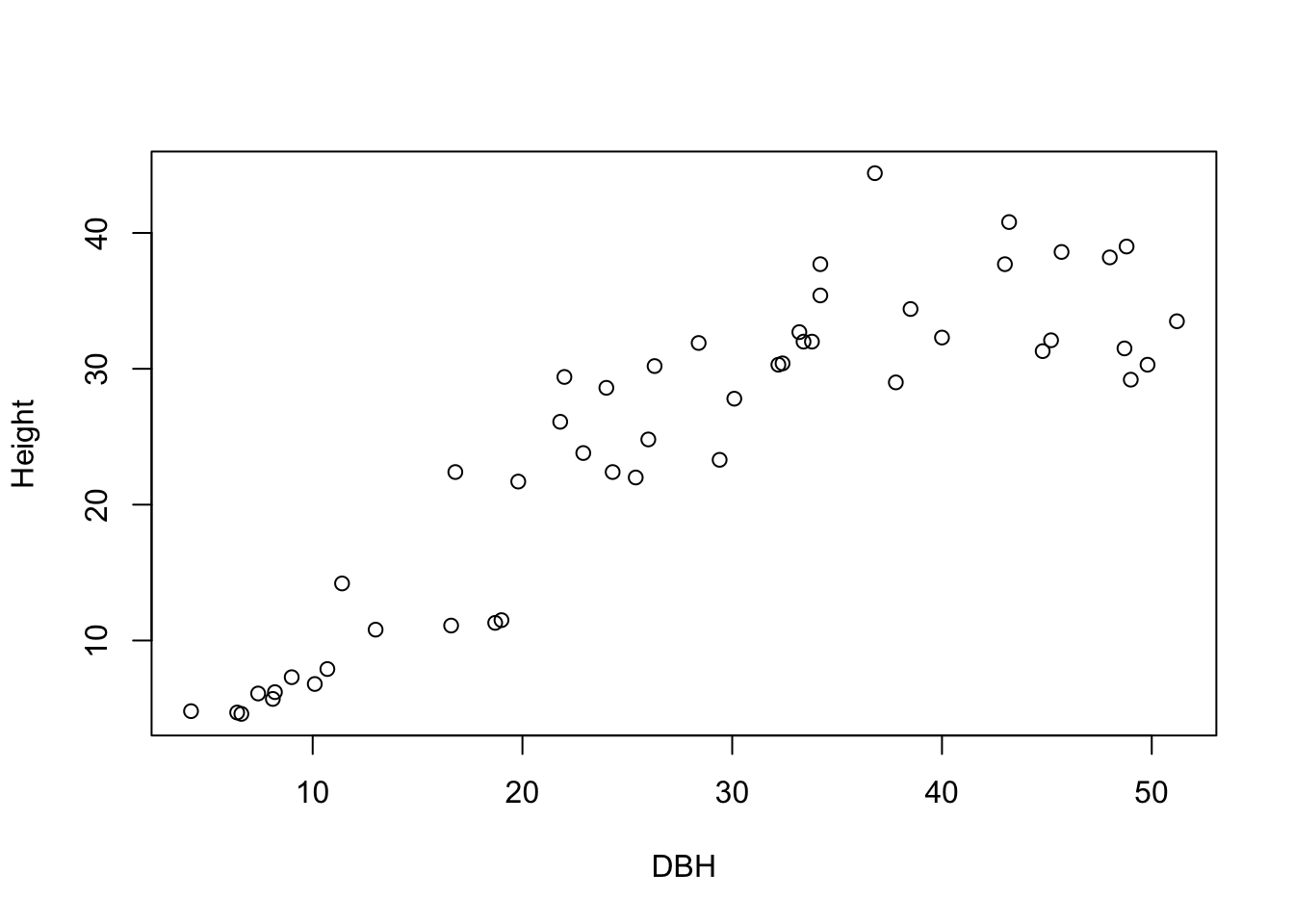
15.1.10 10. Export a plot
When generating a plot within Rstudio, it is by default shown in the Plots window. However, sometimes we want to export a plot and store it in a file for use elsewhere. There are graphics devices that support different formats, such as PDF (vector-based) or PNG (pixel-based). The basic workflow is to start a graphics device and tell it where to store the output file, then create the plot, and finally close the device again. Only if you close the device properly will a valid file be generated. For example, to create a PNG file:
# Open graphics device
png(filename = "/path/to/store/plot.png", # where to store the output file
width = 620, # width of the plot in pixels
height = 480, # height of the plot in pixels
bg = "white") # background color
# Plot something
plot(1:5,rnorm(5), type ='b', col=1:5, pch = 19 )
# Close the device to finish file writing
dev.off()Now, export one of the plots that we generated above to a PNG file, using your favorite background color. (You can also try and use another device, e.g. pdf(), just make sure to use the matching file extension in the file name.)
#### Solution
# Open device
png(filename = "plot.png", # "/path/to/store/plot.png", # where to store the output file
width = 620, # width of the plot in pixels
height = 480, # height of the plot in pixels
bg = "lightskyblue2") # background color
# Scatterplot from section 9:
plot(dbh_height$dbh
, dbh_height$height
, ylab = 'Height'
, xlab = 'DBH'
, main = 'Trees')
# Close the device to finish file writing
dev.off()
## quartz_off_screen
## 215.1.11 11. Calculate mean dbh per species.
For calculating summary statistics, the dplyr package is really helpful. It is part of the tidyverse environment, which was designed for data science. If you work with large and complex datasets or if you have to derive many new variables, I really recommend that you have a look at this. Also, the syntax for dplyr is quite intuitive.
For this exercise, use the dplyr package to calculate mean dbh per species. If you need help on this, check the demonstration of Part 2 where we calculated summary statistics for groups using the dplyr package!
#### Solution
library(dplyr)
treedata %>%
group_by(species_english) %>%
summarize(N = n(),
meanDBH = mean(dbh, na.rm = T),
sdDBH = sd(dbh, na.rm = T))
## # A tibble: 10 × 4
## species_english N meanDBH sdDBH
## <chr> <int> <dbl> <dbl>
## 1 Beech 131 29.6 10.1
## 2 Commom Yew 2 18.8 0.212
## 3 European Ash 12 30.6 4.14
## 4 European Silver Fir 75 11.8 5.55
## 5 Ivy 6 5.13 0.927
## 6 Little Leaf Linden 4 13.3 9.88
## 7 Norway Maple 9 28.2 11.1
## 8 Norway Spruce 15 7.77 1.89
## 9 Scotch Elm 1 17.9 NA
## 10 Sycamore 12 24.0 3.91