11 Recurrent Neural Networks (RNN)
Recurrent neural networks are used to model sequential data, i.e. a temporal sequence that exhibits temporal dynamic behavior. Here is a good introduction to the topic:
11.1 Case Study: Predicting drought
We will use a subset of the data explained in this github repository
utils::download.file("https://www.dropbox.com/s/radyscnl5zcf57b/weather_soil.RDS?raw=1", destfile = "weather_soil.RDS")
data = readRDS("weather_soil.RDS")
X = data$train # Features of the last 180 days
dim(X)[1] 999 180 21# 999 batches of 180 days with 21 features each
Y = data$target
dim(Y)[1] 999 6# 999 batches of 6 week drought predictions
# let's visualize drought over 24 months:
# -> We have to take 16 batches (16*6 = 96 weaks ( = 24 months) )
plot(as.vector(Y[1:16,]), type = "l", xlab = "week", ylab = "Drought")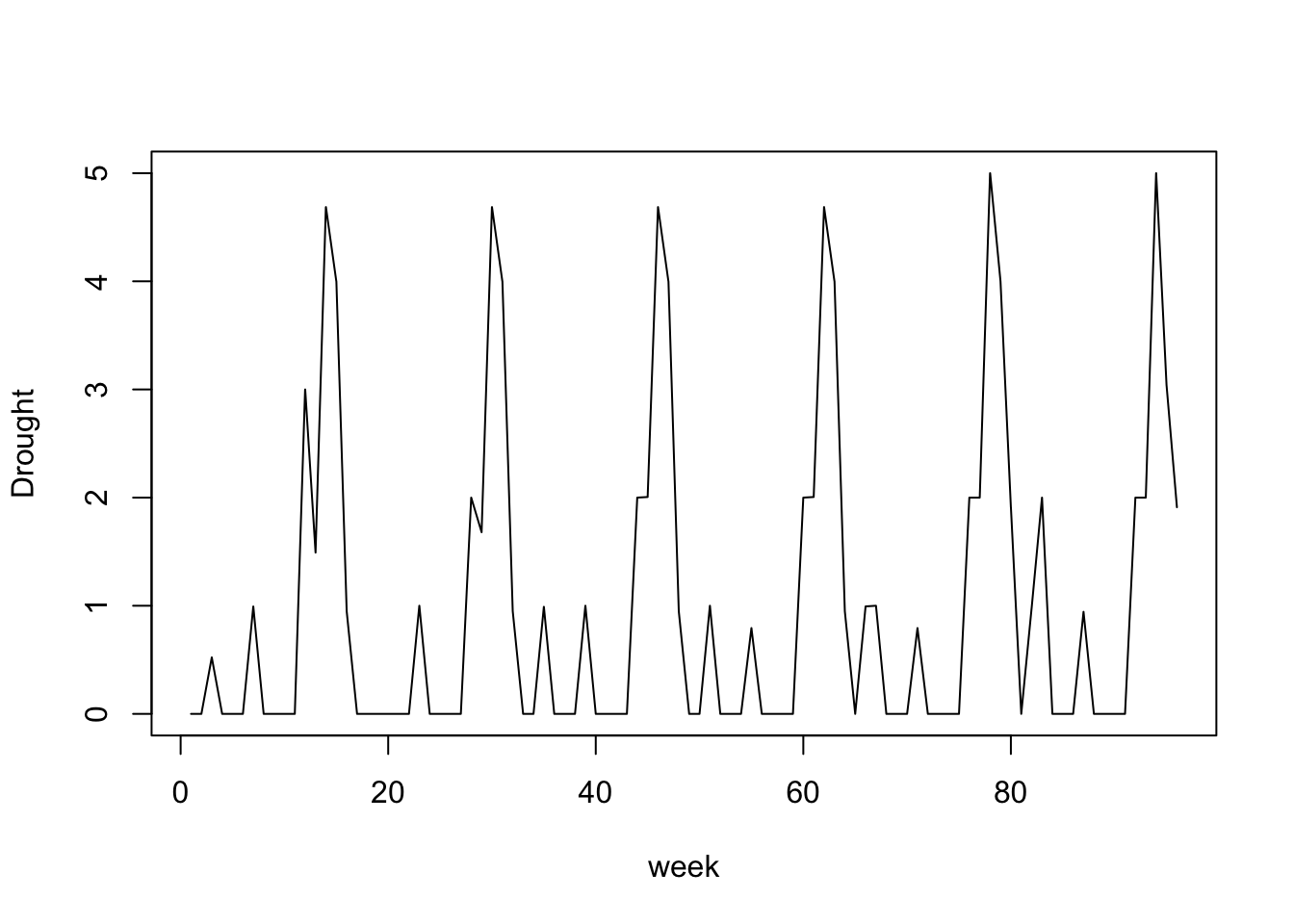
library(torch)
holdout = 700:999
X_train = X[-holdout,,]
X_test = X[holdout,,]
Y_train = Y[-holdout,]
Y_test = Y[holdout,]
net = nn_module(
initialize = function() {
self$lstm = nn_lstm(input_size = 21L, hidden_size = 50L ,batch_first = TRUE)
self$linear = nn_linear(50, 6L)
},
forward = function(x) {
x = self$lstm(x)
# two outputs -> prediction from the last timestep, [batch, seq_len, hidden] , last hidden state
x = x[[1]][,dim(x[[1]])[2], ]
return(self$linear(x))
}
)
# training loop
model = net()
train_dl = dataloader(tensor_dataset(torch_tensor(X_train), torch_tensor(Y_train)), batch_size = 100L, shuffle = TRUE )
opt = optim_adam(params = model$parameters, lr = 0.01)
epochs = 100L
overall_train_loss = c()
for(e in 1:epochs) {
losses = losses_val = c()
model$train() # -> dropout is on
coro::loop(
for(batch in train_dl) {
x = batch[[1]] # Feature matrix/tensor
y = batch[[2]] # Response matrix/tensor
opt$zero_grad() # reset optimizer
pred = model(x)
loss = nnf_mse_loss(pred, y)
loss$backward()
opt$step() # update weights
losses = c(losses, loss$item())
}
)
overall_train_loss = c(overall_train_loss, mean(losses))
cat(sprintf("Loss at epoch: %d train: %3f\n", e, mean(losses)))
}Loss at epoch: 1 train: 1.987364
Loss at epoch: 2 train: 0.893507
Loss at epoch: 3 train: 0.471490
Loss at epoch: 4 train: 0.399569
Loss at epoch: 5 train: 0.364571
Loss at epoch: 6 train: 0.340909
Loss at epoch: 7 train: 0.332033
Loss at epoch: 8 train: 0.337000
Loss at epoch: 9 train: 0.331854
Loss at epoch: 10 train: 0.350917
Loss at epoch: 11 train: 0.333054
Loss at epoch: 12 train: 0.311616
Loss at epoch: 13 train: 0.299763
Loss at epoch: 14 train: 0.287488
Loss at epoch: 15 train: 0.282680
Loss at epoch: 16 train: 0.272073
Loss at epoch: 17 train: 0.303224
Loss at epoch: 18 train: 0.281767
Loss at epoch: 19 train: 0.267751
Loss at epoch: 20 train: 0.281551
Loss at epoch: 21 train: 0.260014
Loss at epoch: 22 train: 0.248619
Loss at epoch: 23 train: 0.245095
Loss at epoch: 24 train: 0.247255
Loss at epoch: 25 train: 0.225355
Loss at epoch: 26 train: 0.214852
Loss at epoch: 27 train: 0.207999
Loss at epoch: 28 train: 0.201104
Loss at epoch: 29 train: 0.213880
Loss at epoch: 30 train: 0.229549
Loss at epoch: 31 train: 0.230646
Loss at epoch: 32 train: 0.255156
Loss at epoch: 33 train: 0.236141
Loss at epoch: 34 train: 0.221463
Loss at epoch: 35 train: 0.210267
Loss at epoch: 36 train: 0.213234
Loss at epoch: 37 train: 0.189317
Loss at epoch: 38 train: 0.176345
Loss at epoch: 39 train: 0.162849
Loss at epoch: 40 train: 0.162676
Loss at epoch: 41 train: 0.148734
Loss at epoch: 42 train: 0.142433
Loss at epoch: 43 train: 0.137399
Loss at epoch: 44 train: 0.133098
Loss at epoch: 45 train: 0.130734
Loss at epoch: 46 train: 0.126104
Loss at epoch: 47 train: 0.127620
Loss at epoch: 48 train: 0.125278
Loss at epoch: 49 train: 0.118294
Loss at epoch: 50 train: 0.118290
Loss at epoch: 51 train: 0.113398
Loss at epoch: 52 train: 0.109100
Loss at epoch: 53 train: 0.104590
Loss at epoch: 54 train: 0.099555
Loss at epoch: 55 train: 0.093563
Loss at epoch: 56 train: 0.091718
Loss at epoch: 57 train: 0.087828
Loss at epoch: 58 train: 0.083765
Loss at epoch: 59 train: 0.081943
Loss at epoch: 60 train: 0.080952
Loss at epoch: 61 train: 0.085244
Loss at epoch: 62 train: 0.079482
Loss at epoch: 63 train: 0.089421
Loss at epoch: 64 train: 0.122584
Loss at epoch: 65 train: 0.130343
Loss at epoch: 66 train: 0.137722
Loss at epoch: 67 train: 0.118895
Loss at epoch: 68 train: 0.124018
Loss at epoch: 69 train: 0.180598
Loss at epoch: 70 train: 0.163526
Loss at epoch: 71 train: 0.141345
Loss at epoch: 72 train: 0.128654
Loss at epoch: 73 train: 0.112311
Loss at epoch: 74 train: 0.096975
Loss at epoch: 75 train: 0.089968
Loss at epoch: 76 train: 0.082798
Loss at epoch: 77 train: 0.078416
Loss at epoch: 78 train: 0.072293
Loss at epoch: 79 train: 0.065630
Loss at epoch: 80 train: 0.063681
Loss at epoch: 81 train: 0.059224
Loss at epoch: 82 train: 0.057515
Loss at epoch: 83 train: 0.053875
Loss at epoch: 84 train: 0.051267
Loss at epoch: 85 train: 0.052241
Loss at epoch: 86 train: 0.051017
Loss at epoch: 87 train: 0.050084
Loss at epoch: 88 train: 0.047428
Loss at epoch: 89 train: 0.045056
Loss at epoch: 90 train: 0.044640
Loss at epoch: 91 train: 0.043873
Loss at epoch: 92 train: 0.042705
Loss at epoch: 93 train: 0.041834
Loss at epoch: 94 train: 0.040757
Loss at epoch: 95 train: 0.043078
Loss at epoch: 96 train: 0.042708
Loss at epoch: 97 train: 0.040529
Loss at epoch: 98 train: 0.039556
Loss at epoch: 99 train: 0.037835
Loss at epoch: 100 train: 0.037984preds = as.matrix(model(torch_tensor(X_test)))
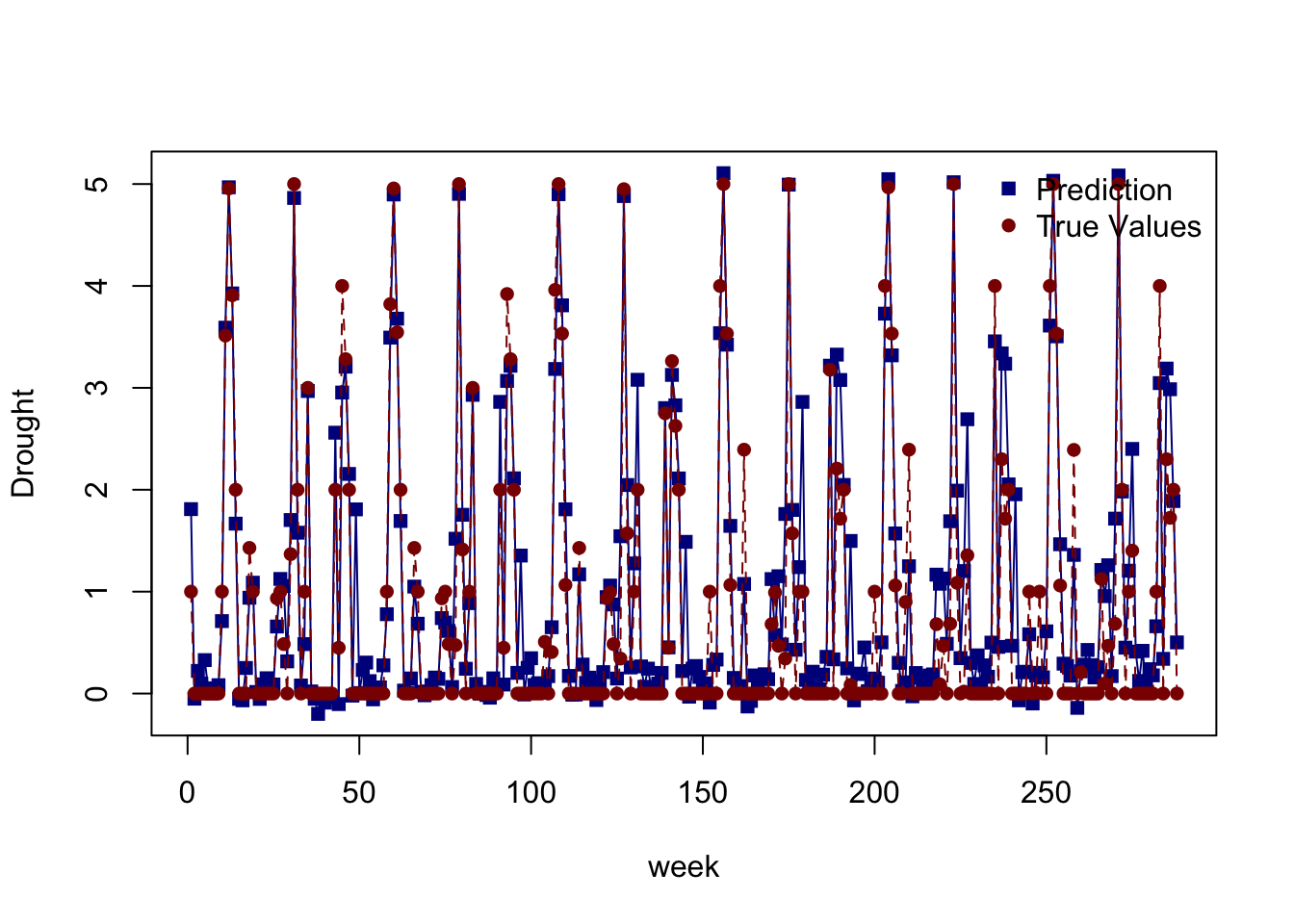
matplot(cbind(as.vector(preds[1:48,]),
as.vector(Y_test[1:48,])),
col = c("darkblue", "darkred"),
type = "l",
pch = c(15, 16),
xlab = "week", ylab = "Drought")
legend("topright", bty = "n",
col = c("darkblue", "darkred"),
pch = c(15, 16),
legend = c("Prediction", "True Values"))