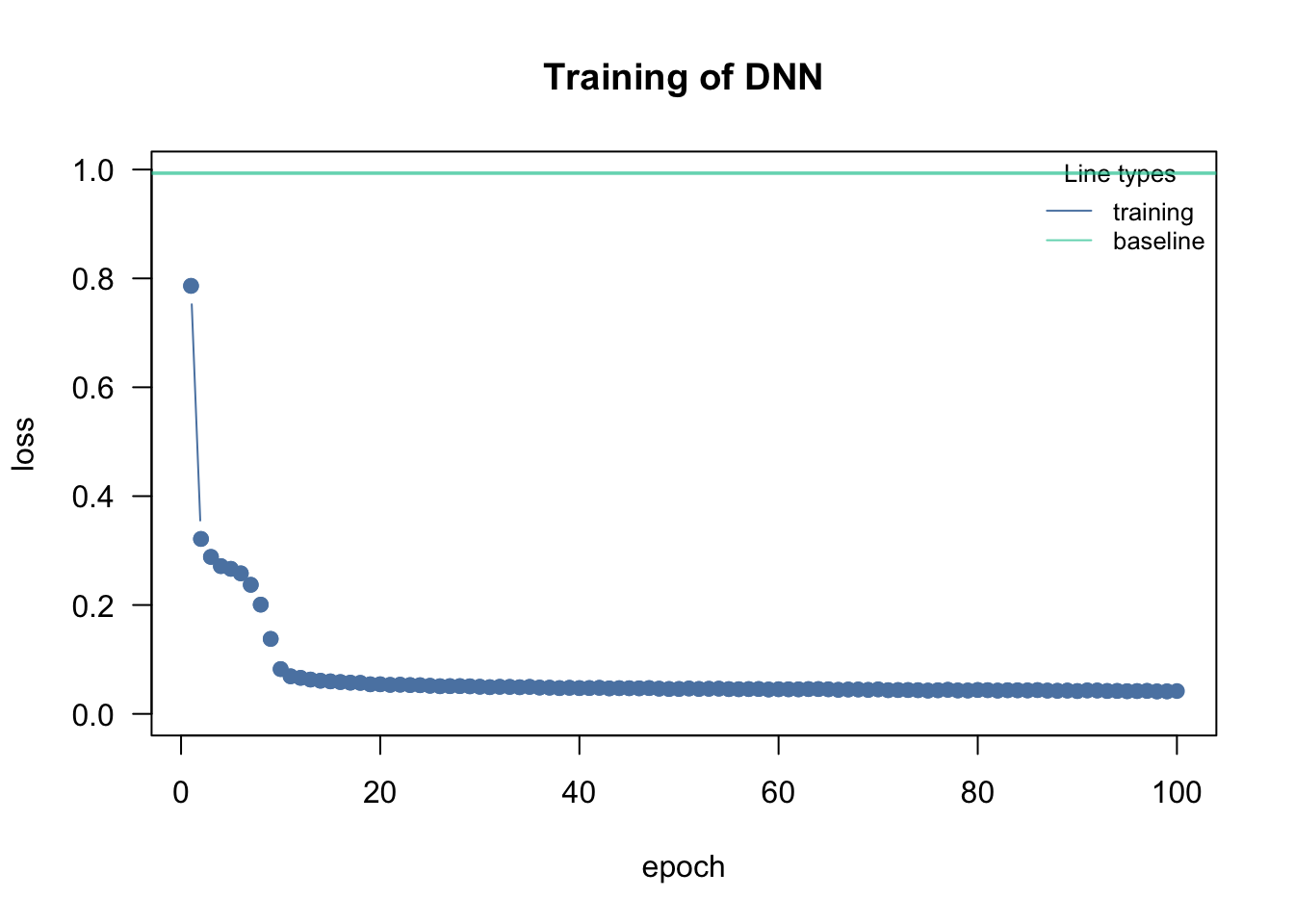
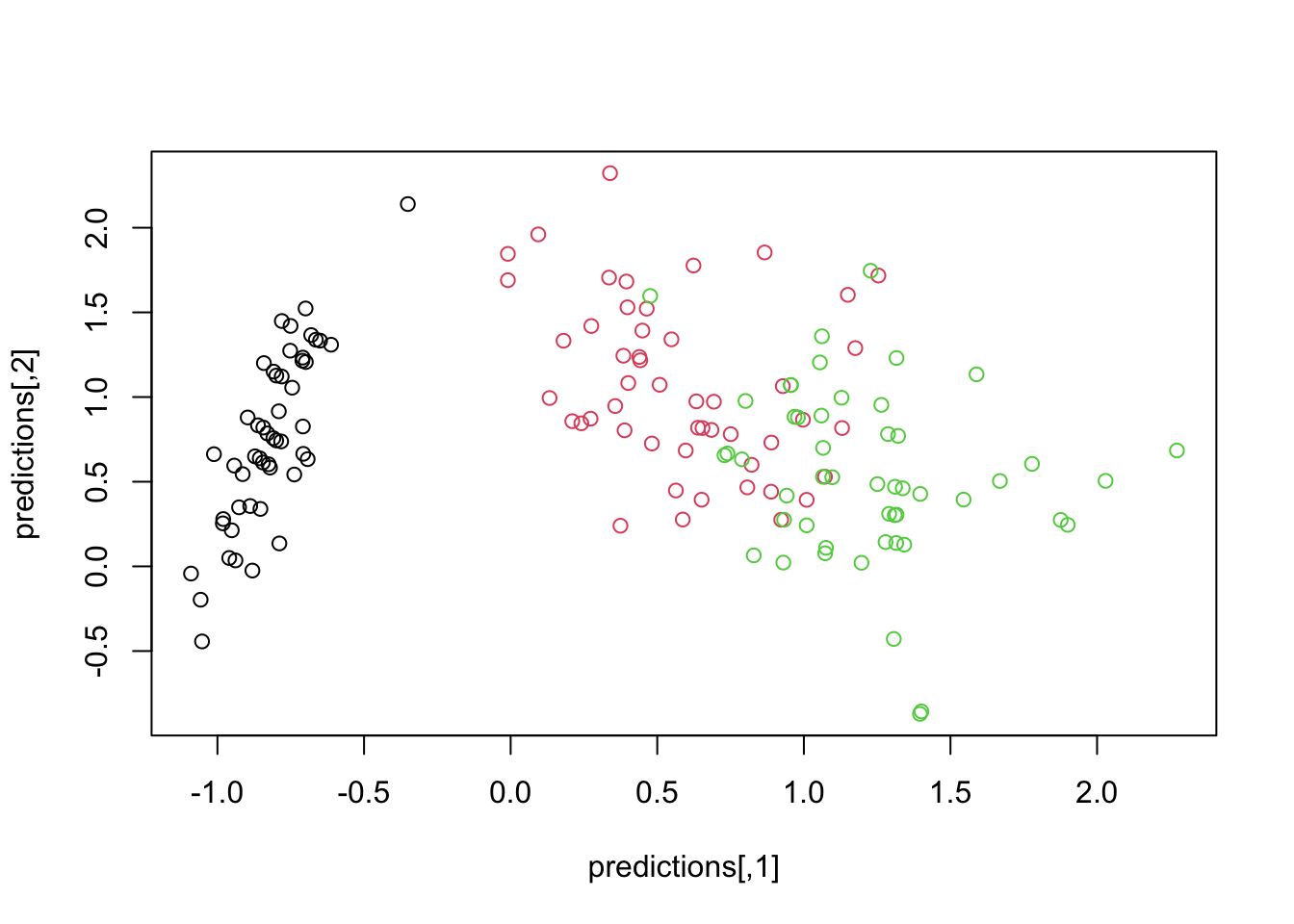
The difference between a variational and a normal autoencoder is that a variational autoencoder assumes a distribution for the latent variables (latent variables cannot be observed and are composed of other variables) and the parameters of this distribution are learned. Thus new objects can be generated by inserting valid (!) (with regard to the assumed distribution) “seeds” to the decoder. To achieve the property that more or less randomly chosen points in the low dimensional latent space are meaningful and yield suitable results after decoding, the latent space/training process must be regularized. In this process, the input to the VAE is encoded to a distribution in the latent space rather than a single point.